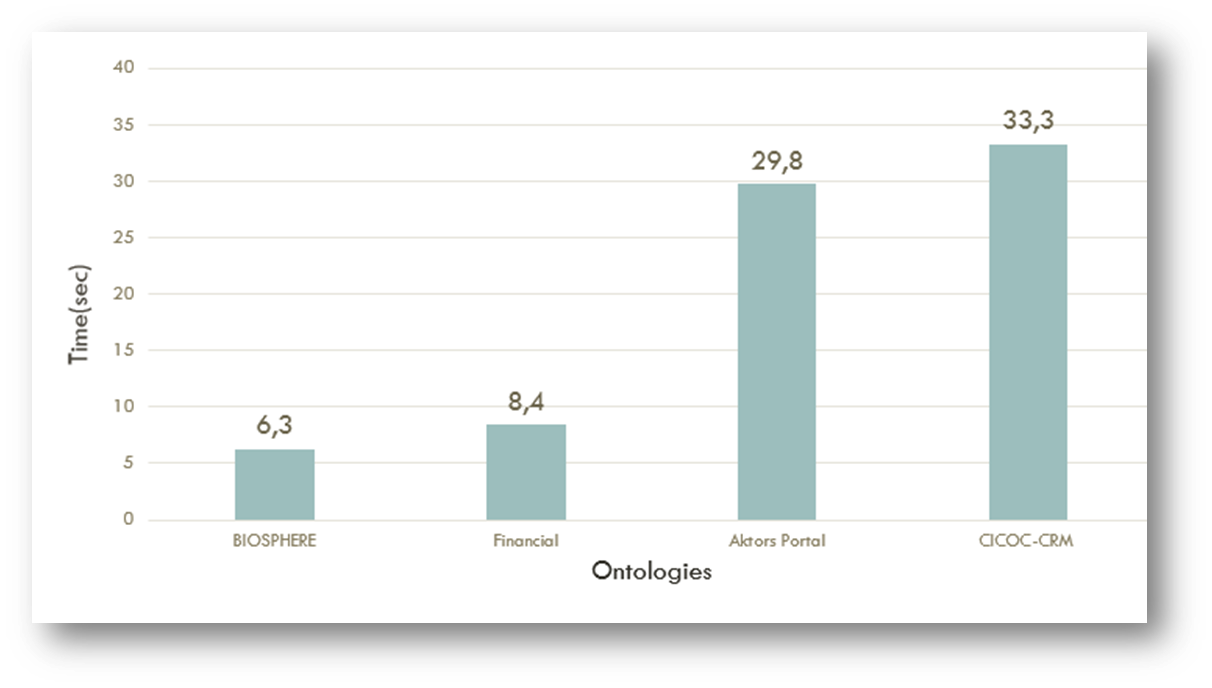
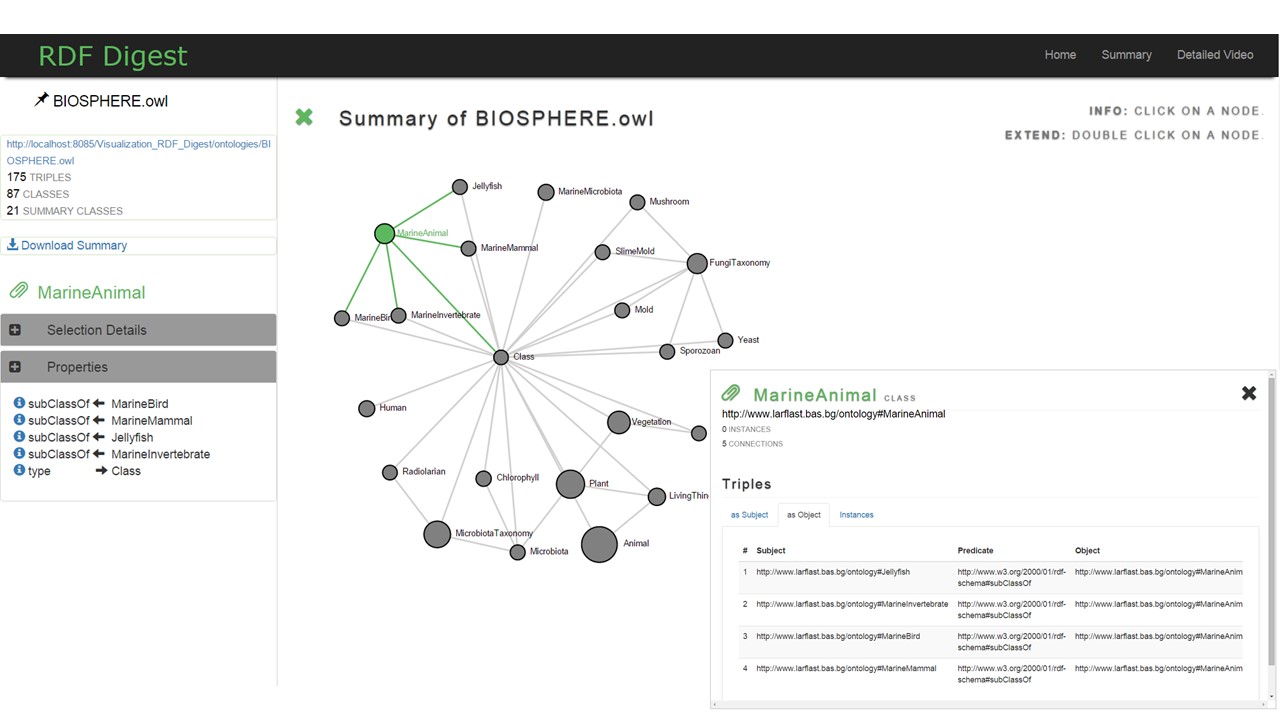
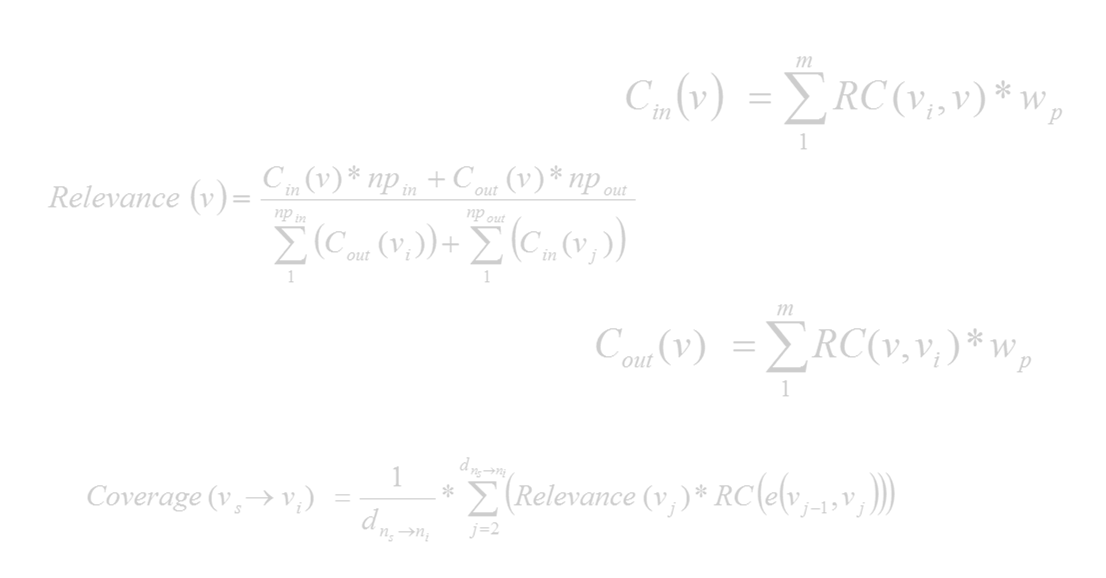Given the explosive growth in both data size and schema complexity, data sources are becoming increasingly difficult to understand and use. Ontologies, often have extremely complex schemas which are difficult to comprehend, limiting the exploration and the exploitation potential of the information they contain. Besides schema, the data contained in them should also drive the identification of the relevant items. Ontology summarization aspires to produce an abridged version of the original ontology that highlights its most representative concepts. We present RDF Digest, a novel platform that automatically produces summaries of RDF/S Knowledge Bases (KBs). A summary is a valid RDFS document/graph that includes the most representative concepts of the schema adapted to the corresponding instances. To construct this graph our algorithm exploits the semantics and the structure of the schema and the distribution of the corresponding data/instances.
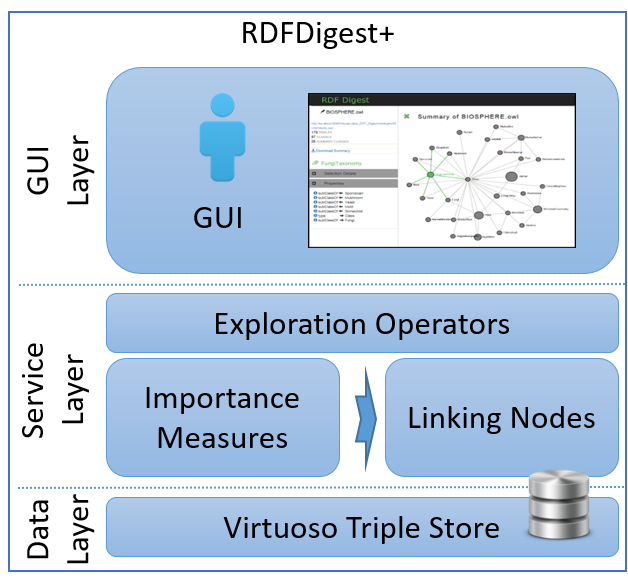
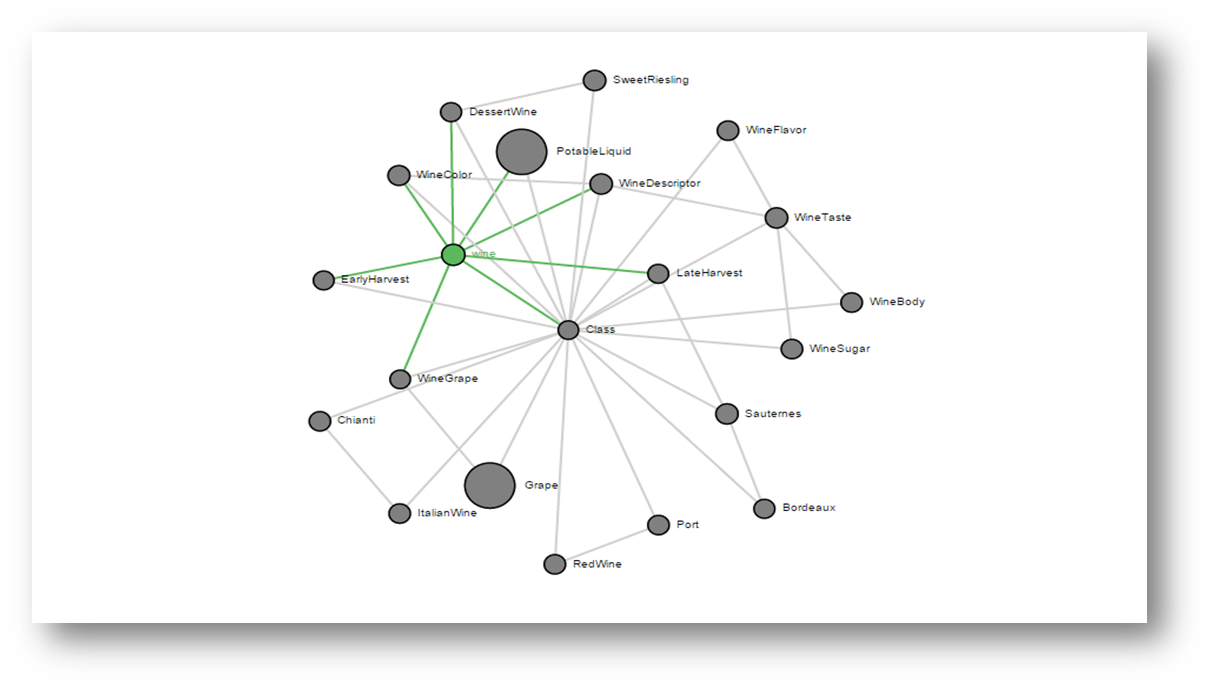
A user can select or give an RDF/S document, he would like to be summarized and he is optionally able to define the expected length of the summary. Moreover he can select the importance measure according to which the most important schema nodes will be selected and the algorithm that these nodes will be connected. When the input is submitted, the RDF/S document is preprocessed and stored in a Virtuoso Instance for efficient data access. Then, the importance and the coverage are calculated for each resource and the summary sub-graph is constructed and visualized. In the presented graph, the size of each node is depending on its Importance. In addition by clicking on a node, additional meta-data (its importance, the number of instances, the connected properties etc.) are provided to enhance ontology understanding. Besides meta-data the properties and the instances of each node are shown and the user can navigate to those by clicking.
We are interested in important schema nodes that can describe efficiently the whole schema and reflect the distribution of the data instances at the same time. To capture these properties, we use the notions of relevance, coverage, and centrality. Initially, we determine how central/important a node is, judging from the instances it contains (relative cardinality). After that, we estimate the centrality of a node in the entire KB (in/out centrality), combining the relative cardinality with the number and type of the incoming and outgoing edges in the schema. Finally, the relevance of a schema node is defined by comparing its centrality with the centrality of its neighbors.